Извлечение образов из мозга человека - от видео до букв
Одним из самых эффектных достижений прошлого года была демонстрация возможности "считывания" видео-фрагмента из мозга человека. Это событие стало закономерным шагом в целой череде экспериментов по "чтению мыслей".
Новейшая техника позволила распознать по изменениям в поведении нейронов в коре головного мозга, что именно видит человек перед собой. Если прогресс пойдет тем же темпом, то уже в ближайшем будущем мы сможем не только понять, чем взгляд на мир одного человека отличается от другого, но и увидеть на экране компьютера собственные сны и фантазии.
На фото выше микрофотография коры головного мозга человека, сделанная с помощью сканирующего электронного микроскопа
Кора полушарий мозга человека имеет толщину от 1,3 до 4,5 мм. Площадь же её составляет в среднем 22 квадратных метра. Такая площадь возможна из-за борозд и извилин, покрывающих наш мозг. В среднем, кора составляет 44% всего объема полушария.
Структура коры головного мозга позволяет уживаться в ней более 14 млрд нервных клеток. В коре клетки и волокна расположены слоями (в среднем шесть слоев). Их упаковка такова, что длина всех связей нейронов в мозге человека в целом составляет более миллиона километров.
Именно в коре локализуются клетки, ответственные за высшие функции нашей психики. Узнать структуру и конкретные функции этих клеток (что невозможно без знания о связях между ними) - важнейшая задача современности.

Первый успешный эксперимент по "извлечению образов" из мозга человека был проведен 4 года назад. И результатом его стало, ни много ни мало, успешное прочтение "в голове" добровольца тех букв, которые тот видел перед собой.
Прорыв совершила большая команда японских исследователей из пяти национальных институтов и лабораторий под руководством Юкиясу Камитани, Йочи Мияваки и др.
В коротком пересказе опыт предельно прост: добровольцам предъявлялись большие черно-белые изображения, построенные из 100 "пикселей" (10 на 10 квадратиков) - с их мозга с помощью фМРТ снимались данные - на основе этих данных компьютер проводил реконструкцию того, что видит перед собой человек.

Вверху - те стопиксельные изображения, которые предъявлялись человеку. Затем идет серия попыток "извлечения информации из мозга". В самом низу - обобщенный результат распознания.
Хорошо видно, что даже после однократного прохода в большинстве случаев исходные изображения вполне узнаваемы, не говоря о финальном результате
Как хорошо видно на иллюстрации - результат распознания весьма впечатляющий. А ведь фМРТ "всего лишь" фиксирует изменения в кровотоке рядом с той или иной группой нейронов. Но построенные модели работы зрительных нейронов и "самообучающиеся" алгоритмы позволили-таки увидеть видимое человеком.
Перед каждым сеансом происходило обучение программы - её настройка на каждого из добровольцев. Человеку каждые 6 секунд предъявлялись около 500 стопиксельных изображений и компьютер выстраивал соответствия между информацией об активности мозга, поступающей от фМРТ, и каждым из изображений.
В результате для каждого "пикселя" из матрицы 10 на 10 программа определяла вероятность того, будет ли он черным или белым, если активна та или иная группа нейронов. Причем матрицу приходилось просчитывать на нескольких масштабах одновременно - вычисляя соответствия не только для каждого отдельного пикселя, но и для их определенных конфигураций.
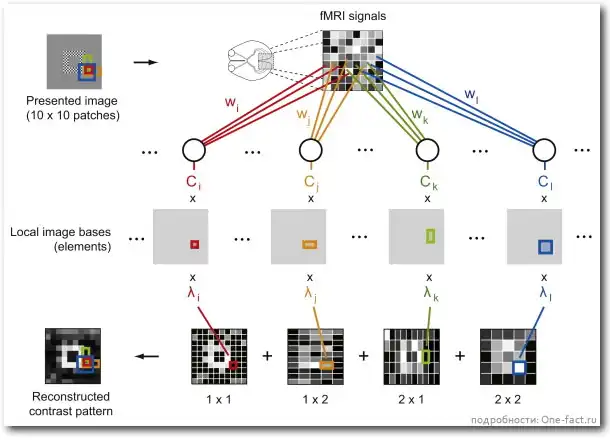
Несмотря на вроде бы маленький размер картинки, объем возможных сочетаний, если подходить к нему впрямую, мог дать гигантскую цифру: два в сотой степени вариантов. Но найденные алгоритмы выделения значимых данных в информации фМРТ позволили уже на существующей в 2008 году технике проводить надежное "извлечение" изображения из мозга человека всего за 2 секунды
Но вернемся к эксперименту 2011 года. Прорыв к раскодированию видеообразов в нашем мозге был совершен в Университете Беркли Шинжи Нишимото и его соавторами
Эксперимент частично осуществлялся по той же схеме, что и распознавание статичных картинок. Вначале испытуемый в течение нескольких часов смотрел короткие видеофрагменты, а компьютер пытался провести соответствие между тем изображением, что видит человек, и получаемыми фМРТ-данными. В результате создавалась индивидуальная компьютерная модель, которая определенной активности мозга человека ставила в соответствие видеофрагменты определенного содержания.
Затем человеку демонстрировался новый ролик, и программа пыталась воссоздать по сигналам его мозга, что же он видит. Для этого программа отбирала из нескольких миллионов заранее обработанных роликов с YouTube 100 видеофрагментов, которые, согласно её алгоритмам, наиболее соответствовали данной специфике сигналов мозга. После этого отобранные видеофрагменты покадрово смешивались и в результате получалось усредненное изображение, которое с наибольшей вероятностью, по мнению программы, и видел человек. Вот презентация полученных результатов:
На видео очень хорошо видно, насколько уже сейчас удается достаточно близко "распознать" форму и цветовую гамму исходного изображения. И это только первый опыт
Понятно, что намечены пути решения задачи на порядок более сложной, чем "извлечение" из мозга статичной картинки. Дело в том, что фМРТ достаточно медленный метод распознания (ведь в его основе, по сути, сигналы об уже совершенном нейронами питании после их активной работы) и лишь надежная модель поведения нейронов, при получении той или иной информации из "внешнего мира", может позволить обрабатывать такой неповторяющейся процесс, как просмотр нового видео. А раз эта задача решена, то значит, исследователям удалось еще ближе приблизиться к надежному понимаю того как работает кора (по крайней мере зрительная) нашего мозга.
Ну а если говорить более конкретно, то на основе проведенного эксперимента уже сейчас можно попытаться анализировать индивидуальные особенности восприятия человеком окружающего мира. Попытаться выяснить, что видит новорожденный или, например, человек с психическим заболеванием.
А если окажется, что схема работы нейронов ответственных за непосредственное восприятие схожа со схемой работы нейронов, когда человек нечто воображает или видит сны, то данный эксперимент - это, по сути, первый шаг к "документальной съемке" нашего внутреннего мира.